Ethernet Reimagined: How the Tomahawk Ultra Scales AI and HPC Workloads
Ethernet Reimagined: How the Tomahawk Ultra Scales AI and HPC Workloads" highlights Broadcom’s Tomahawk Ultra as a transformative Ethernet switch designed to meet the extreme demands of modern AI and HPC environments. With 51.2 Tbps of bandwidth, ultra-low latency, and advanced features like in-network intelligence, RoCE support, and adaptive routing, it offers a scalable, energy-efficient alternative to InfiniBand. Optimized for GPU-heavy workloads and scientific computing, the Tomahawk Ultra enables faster model training, real-time inference, and high-performance simulations positioning itself as a key enabler of next-generation data center innovation.
8/6/20253 min read
Ethernet Reimagined: How the Tomahawk Ultra Scales AI and HPC Workloads
In the rapidly evolving landscape of High-Performance Computing (HPC) and Artificial Intelligence (AI), the demand for faster, more efficient, and scalable networking solutions has never been greater. Enter the Tomahawk Ultra: a next-generation Ethernet switch that redefines what is possible in large-scale computing environments.
Designed to meet the rigorous demands of modern HPC and AI workloads, the Tomahawk Ultra sets new standards for performance, scalability, and energy efficiency.


The Need for Speed in HPC and AI
As HPC and AI applications grow in complexity and scale, the underlying infrastructure must keep pace. Traditional Ethernet switches, while reliable, often struggle to handle the massive data throughput and low-latency requirements of these workloads.
AI training, for instance, involves the simultaneous processing of vast datasets across thousands of GPUs, requiring seamless communication between nodes. Similarly, HPC applications like molecular modeling and climate simulations demand ultra-fast data transfer to deliver timely results.
The Tomahawk Ultra addresses these challenges directly, offering unprecedented performance and scalability. Its architecture is engineered to support the most demanding workloads, enabling researchers and engineers to push the boundaries of innovation.
Supports in-network intelligence and on-chip collectives
Enables predictable, high-efficiency performance for large-scale simulations and scientific computing
Provides a viable Ethernet alternative to InfiniBand, with open standards and broader ecosystem support
Key Features of the Broadcom Tomahawk Ultra
Ultra-High Bandwidth The Tomahawk Ultra delivers 51.2 Tbps of switching capacity, making it one of the fastest Ethernet switches on the market. This immense bandwidth ensures data can move freely across the network, minimizing bottlenecks and maximizing throughput. It supports up to 77 billion packets per second, even with minimum-sized packets, which is critical for HPC workloads using MPI and SHMEM APIs.
Low Latency In HPC and AI environments, even microsecond-level delays can significantly impact performance. The Tomahawk Ultra is designed with ultra-low latency, routing data packets with minimal delay. It achieves 250 nanoseconds of switch latency at full 51.2 Tbps throughput, making it ideal for real-time data processing.
Scalability (Scale-Out and Scale-Up) The Tomahawk Ultra is built to scale. Its modular design allows seamless integration into existing networks, while support for features like RoCE (RDMA over Converged Ethernet) and Multi-Path Routing ensures optimal performance in large deployments. Scale-Up Ethernet (SUE) enables sub-400ns XPU-to-XPU communication latency, including switch transit time, making it ideal for synchronized AI model training and inference.
Energy Efficiency As data centers grow, energy consumption becomes a critical concern. The Tomahawk Ultra incorporates advanced power management techniques to reduce energy usage without compromising performance. This contributes to both lower operational costs and a more sustainable infrastructure.
AI-Optimized Features Recognizing the unique demands of AI workloads, the switch includes adaptive routing and load balancing to ensure efficient training and inference, even in dynamic network environments.
Lossless Fabric with Optimized Ethernet Headers The switch implements Link Layer Retry (LLR) and Credit-Based Flow Control (CBFC) to eliminate packet loss. It reduces header overhead from 46 bytes to as low as 10 bytes while maintaining full Ethernet compliance and improving overall efficiency.
Photo Credit: Broadcom
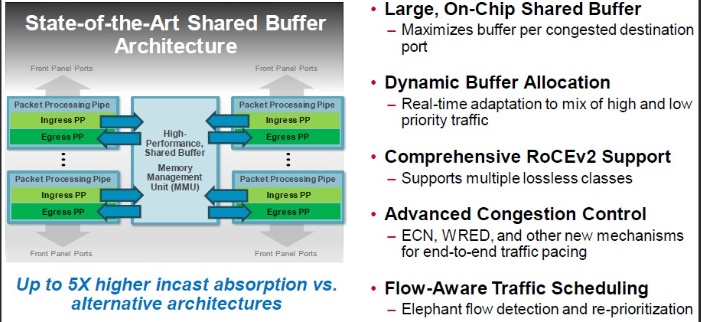
Picture Credit: The Next Platform
Architectural Shift
The Tomahawk Ultra represents a fundamental departure from traditional Ethernet switch design.
Prioritizes latency over aggregate throughput
Optimized for minimum packet size streaming, a key requirement in HPC and AI
Designed for GPU scale-up in next-generation AI infrastructure
Applications in HPC and AI
AI Training and Inference High bandwidth and low latency enable faster model training and responsive inference, especially in multi-GPU environments.
Scientific Research From genomics to astrophysics, the switch accelerates simulations and data analysis for faster breakthroughs.
Financial Modeling In finance, where milliseconds matter, the switch ensures that trading algorithms and risk models operate with optimal speed and precision.
Cloud Computing The Tomahawk Ultra supports large-scale, multi-tenant environments with the bandwidth and scalability required by leading cloud providers.
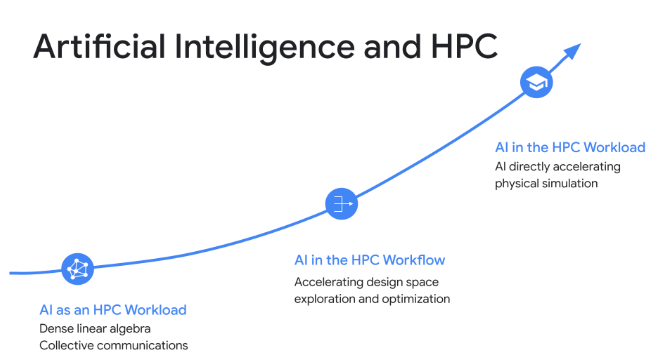
Photo Credit: roboticontent
The Future of Networking
The Tomahawk Ultra represents a significant leap in Ethernet switch technology. By reimagining the role of the network in HPC and AI, it enables a new era of innovation and discovery.
In a world where speed, scalability, and efficiency are critical, the Tomahawk Ultra is more than just a switch. It is a catalyst for progress. Whether training the next breakthrough AI model or simulating the cosmos, the Tomahawk Ultra is the networking solution of choice.